Memory Techniques - Part 2
14 minute read •
(Part 2 - Algorithms and Techniques)
So, you already know how to load and view a 4Gb file because you’ve just finished reading Part 1 of this article series. Now you know how manage large amounts of memory, we can move on and explore a very powerful technique for actually editing a large file.
Let’s have a quick recap of the original task at hand. We are developing a file editor capable of loading, viewing and editing a 4Gb file, which is the biggest file size currently supported by both Windows 9x and Windows NT/2000. I presented the source-code to the HexView mini-application, which is currently just a very simple file viewer with no editing capabilities. I also presented the sequence class, which represents a file, or sequence of bytes in an abstract manner.
The article will present an overview of the span-table data structure, which is used is the same data structure used by HexEdit to manage its files. The source-code supplied builds on the sequence class to use the span-table data structure. I’m not going to be getting down to any low-level coding, so you’ll need to look at the sources if you want to see how its done.
Inserting and deleting data from a file
The best way to describe what this means is to use a diagram. The example below shows a file containing part of the well known saying “The quick brown fox jumped over the lazy dog”. The file itself has the word “brown” removed from it. To illustrate the action of inserting text into a file, the word “brown " is inserted into the file to produce the proper saying.
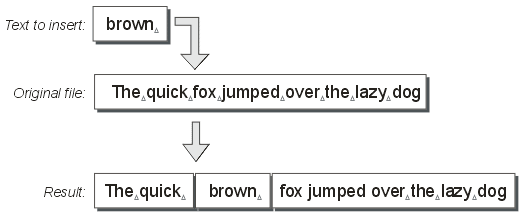
Figure 1
By inserting or deleting data from a file, you can see that the file contents has to be shifted around to make room for the new data, or in the case of deletions, to overwrite the portion of the file that we want to delete. For now I’ll concentrate on inserting data into a file, because the same principles apply if we delete data as well.
Solution #1 – Quick to code but slow to execute
The easiest and most obvious method to insert data is to take a two-step approach:
- Shift along the file contents after the insertion point to make room for the inserted data
- Copy the data to insert into the space left by the shifted portion of file.
Whilst this seems like a perfectly good solution, the technique becomes seriously compromised when large amounts of data need to be shifted around. Think about inserting one character into a 4Gb file using a file editor – if the character is inserted at the start, the entire 4Gb needs to be shifted along to make room for this single insertion. This operation will take a very long time to complete, and is not an acceptable solution.
Solution #2 – The Span Table
The answer is to represent the large 4Gb file in some other way than a simple buffer or array. Whilst there are many different data structures which can be used to represent a file in an editor, there is only one sensible choice for our multi-gigabyte hex editor.
It is called a span-table (or piece-table). The name derives from the fact that a file is represented as a series of spans (or pieces) of data. These spans provide a level of indirection to the contents of the file. Whilst the file itself remains as a contiguous block of data, access to the file is always through the span-table. Instead of editing the file contents when an edit occurs, the span-table is modified to reflect the edit. The under-lying file contents will always remain unchanged, but because the span-table has been modified, it will reflect the contents in a different manner.
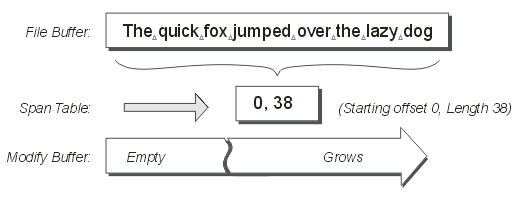
Figure 2
The diagram above illustrates an unmodified file, with the span table containing a single span which encompasses the whole file.
What is a span?
Glad you asked. A span is just a very simple data structure which contains enough information to represent a range of data in a file. The technical term for a span is probably a “descriptor” or something like that, but I prefer the name “span” because it is short and to the point. This is what a span would look like if you were using C or C++.
struct span
{
unsigned int buffer; /* identifies the buffer this span references */
unsigned int offset; /* start of the range of data this span covers */
unsigned int length; /* length of data */
span *prev, *next; /* linked-list */
};
Pretty simple, right? Figure 2 (above) illustrates a span with offset 0 and length 38, but does not show the value corresponding to the buffer. I have delibrately not shown the “buffer” id in the examples on this page because it is not really necessary for these simple examples (you can see for yourself what buffers are being used). Also, it keeps the diagrams simpler without the extra numbers flying around.
What is a span table?
A span table is any data structure used to collect a series of spans together in a sequential order. In my HexEdit application I use a doubly linked list to store the spans.
Apart from the actual span-list, there are two other important data structures used by our data sequence.
- The first is a read-only buffer containing the file’s contents. This file-buffer never changes! The buffer is loaded once when the span-table is initialized. By using operating system support (in our case, memory-mapped-files) this load can be very quick, especially because we only need read-only access.The “filebuffer” will have a buffer-id of 0 (zero).
- The second is an append-only buffer which over time contains any inserted data. This buffer must obviously have write access, and must be capable of being resized. When the span-table is initialized, the “modifybuffer” is initally empty. It has a buffer-id of 1 (one).
There are obviously going to be other variables used by our span-table, but the three mentioned so far are the most important. Also, it doesn’t really matter what id’s you give to the file and modify buffers - as long as they are unique, you can use any scheme you want.
Inserting data into the span table
Now the fun begins. The first example will be the same as the original (inserting the text " brown” into the sequence at offset 9 - note the leading space). The diagram below shows the span-table after the text has been inserted.
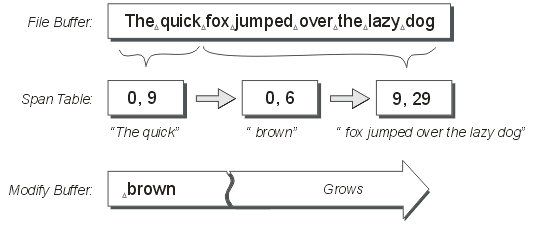
Figure 3
The thing you must look at here is the spans in the span table. The original span which covered the whole file buffer has been replaced with three new spans. The first span refers to the data before the insertion point. The last span refers to the data after the insertion point. Both of these spans’ lengths and offsets are set so that the spans cover the correct ranges of data. Also, both spans still have the same buffer-id.
The middle span references the inserted data (the word " brown"). This text has been appended into the modify-buffer. The middle span’s offset and length are set to refer to just this string of text.
Hopefully you have appreciated what has happened so far. If you don’t quite “get it” yet, then sit back and stare good and hard at the diagram until it sinks in!
Inserting even more data into the span table!
Our sequence now contains the text “The quick brown fox jumped over the lazy dog”.
The next example shows the span-table after the text “est " has been inserted (at index 9 again). Please note that this index does not refer to an index the original file, but to the logical position in the sequence.
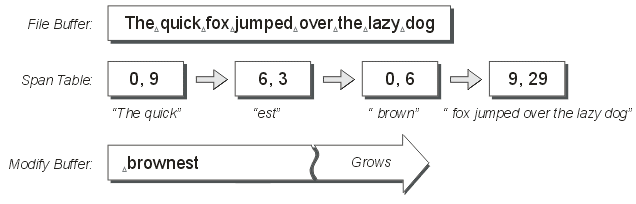
Figure 4
This time you will see that the only one new span has been inserted into the span-table. The insert occured at a position in the sequence which was at a span boundary. In this case, a single span was inserted with the text “est”. The inserted text has also been appended to the modify-buffer. Our sequence now holds the text phrase “The quickest brown fox jumped over the lazy dog”.
What does this mean?
It means we can insert any amount of data to any position in a file! This insertion process can be divided into three separate cases. The main difference occurs when data is inserted at a position in the sequence which is either in the middle of a span, or in-between two spans (on a “span boundary”).
- Inserting data in the middle of a span.
In this case, the span must be replaced with three new spans - spans which represent the data before the insertion point, after the insertion point, and actual the inserted data itself. - Inserting data at a span boundary. When text is to be inserted in this case, only one new span is required (to represent the inserted text). This new span can be simply linked in-between the two spans which reside either side of the insertion point (or index).
- Inserting immediately after a previous insertion.
This is a special case. No new spans are created. Instead, the previous inserted span’s length is adjusted to include the new data, and this data is simply appended to the end of the modify-buffer. This saves memory because no new spans are created, and also keeps the span-table as simple as possible.
Deleting data from the span table
The next logical operation to cover is the act of deleting data from the sequence. As always, a picture speaks a thousand words, so here’s a diagram. In this example, the data from offset 9 to 29 (20 bytes) has been removed from the original sequence, to produce the phrase “The quick lazy dog”.
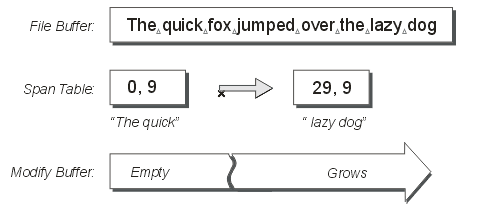
Figure 5
What has happened here is that the single span covering the original file has been split into two new spans, the first to represent the data before the deletion, and the second to represent the data after the deletion. Hopefully you can use your imagination to realise the further possibilities of span manipulation.
This data removal can be divided into three separate cases.
- Deleting data from the middle of a span. This is the case described in the above diagram. In this case, the span is replaced with two new spans, the first to represent the data before the deletion, the second for the data after the deletion.
- Deleting on a span boundary (at the start or end of a span).
In this case, the existing span’s offset (when deleting at the start of a span) or length (when deleting at the end) can be simply modified to reflect the change. - Deleting data which is covered by several spans.
This is the worst case, and requires careful coding. In this case, several spans may need to be removed from the list to represent the new sequence of data.
Replacing data (over-writing)
Data replacement is a hybrid form of insertion and deletion. I won’t describe the process here, and I advise anyone not to attempt this operation until they have a fully functional delete operation.
The fundamental steps are the same as those of the delete (or removal) operation. Existing spans in the table must be removed to make way for the new data. Instead of simply linking the two halves of the sequence back together after the deletion (as happens with the delete method), a new span is inserted into the table to represent the new over-writing data. This is where the similarity of the insert operation comes into play.
Multi-level Undo and Redo
I won’t describe in detail how to achieve this, but just give a very simple overview instead.
I have been talking throughout this discussion on replacing spans with new spans, and so on. What I didn’t talk about was what to do with these spans once they have been removed from the span-table. The obvious thing to do is just to delete them (i.e. with the C++ delete[] operator), but there is a much better solution.
Any span that is removed during a span-table “edit” is added to a stack (of spans!). These spans still have their linked-list pointers (prev, next) left untouched. So, the spans on the undo-stack still point to valid spans in the span-table, even though they aren’t in the table themselves.
When the time comes to undo the last edit, we perform two steps. The first is to pop off the spans from the undo-stack, and look at their linked-list pointers. This tells us exactly where in the span-table to put these spans back into! The second thing to do is to take the “newer” spans in the table that our undo-spans replace, and push them onto the redo-stack! Can you see where this is going…?
The concept is simple, and the implementation is not much more difficult. Just look in the sources to see it in action!
Rendering the span-table
It’s all well and good inserting and deleting data from our sequence, but it doesn’t mean a thing unless we have some way of actually viewing the sequence contents.
This is actually a very simple process. All we do is a linked-list traversal, visiting each span in turn, and retrieving the region of data from the buffer that the span represents. This is what your code might look like:
span *sptr = spanhead; // spanhead points to the first span in the list
while(sptr != 0)
{
char buf[100];
// get a pointer to the memory that this span refers to.
char *mem = get_adjusted_ptr(sptr->buffer, sptr->index);
// copy the data that this span represents into our local buffer.
memcpy(buf, &mem[sptr->index], sptr->length);
//null-terminate.
buf[sptr->length] = '\0';
//print it out!
printf(buf);
//goto the next span!
sptr = sptr->next;
}
Remember the get_adjusted_ptr function from the previous article? This is where it pays off - you can see how simple the above loop is. The beauty of the design of the span-table is that it doesn’t matter which buffer / file a span refers to - at the end of the day, it is just a block of memory, and the get_adjusted_ptr function performs the hard work of retrieving that memory for us.
Conclusion
As you can see, the span-table is a very flexible method to implement modifications to a file, or sequence of data. Because edits to the span table can be achieved in constant time, it does not matter how big the under-lying file is - inserting data into a 1Kb file takes the same time as inserting into a 1Gb file.
There are disadvantages to using the span-table method though, but these are managable.
The first problem comes when it is time to save the sequence back to disk. The entire sequence must be rendered into a temporary file, which is then copied back over the original file (and the sequence re-initialized with this new file, and the span-table reset also). We can cope with this though. This is a one-time operation, and all the memory copying only occurs this once, instead of every time a modification occurs as is the case with other file handling methods.
The second problem is indexing a particular byte in the sequence. Because we are using a linked list of spans, it is not possible to jump directly to a particular position in the span-table. Therefore to locate a specific span, we need to traverse the span-table from the start each time. This is fine when there haven’t been many edits to the table (and the list is short), but could become time consuming if there are many thousands of spans in the table.
This is not as bad as it seems though. We can operate some form of span caching, to reduce the number of span traversals needed to locate a particular span. We can also optimize inserts and deletes (described in their appropriate sections), so that when appropriate we can concatenate inserts and deletes into a single operation, thus reducing the span-count in the table. The last thing to bear in mind is that it isn’t very likely that someone will make thousands of seperate modifications to a file in our hex-editor without periodically saving the sequence, so in reality these negative points don’t come into effect. Just download the HexEdit application from this site and see for yourself how fast this span-table method is!
Full source available!
You may have noticed the size of the download at the top of this page. This is the full source-code to the HexView library I use in my HexEdit application. That’s right, the full source. Included is a complete implemention of the span-table, encapsulated by the sequence class. This library comes complete with absolutely NO SUPPORT what-so-ever! Unless you have any comments or suggestions for improvement, then I probably won’t be able to help you out unless you have a very simple question - I really don’t have the time (or the inclination) to support something like this. Afterall, I’m doing this for free, and in my spare time.
Coming soon – Part 3
I havn’t decided what the next article in this series is going to be yet. If you have a particular aspect of the span-table you’d like me to cover, then feel free to email me
Have fun! James.