More Uniscribe Mysteries
11 minute read •
Uniscribe Mysteries continued…
We are going to pick up directly from where we left the last tutorial, in which we began to look at the Uniscribe API in detail. Remember that we are still working on the UspAnalyze function, and the sequence of events last time had led us to the point where we had broken a string of Unicode text into several item-runs. Below are the steps we made to get this far:
ScriptItemize- to break the string into distinct scripts or “item-runs”.- Merge item runs with application-defined “style” runs to produce finer-grained items.
ScriptLayout- to potentially reorder the items.
The result of this work was an array of ITEM_RUN structures (called itemRunList) and the visual-logical mapping array (called visualToLogicalList) - which tells us in what order to display the runs. Both these arrays are stored inside the USPDATA object:
struct USPDATA
{
...
ITEM_RUN * itemRunList;
int itemRunCount;
int * visualToLogicalList;
...
};
The next task is to take each item-run in turn and get to the point where we can actually render some text (using ScriptTextOut). This will involve calling two more closely related Uniscribe functions (ScriptShape and ScriptPlace) for each run. Below are the steps we will now follow:
ScriptShape- to apply contextual shaping behaviour and convert the characters from each run into a series of glyphs.ScriptPlace- to calculate the width and positions of each glyph in the run.- Apply colouring/highlighting to the individual glyphs.
ScriptTextOut- to display the glyphs
4. ScriptShape
Of all the Uniscribe functions, ScriptShape is probably the most important. It’s purpose is to convert a run of Unicode characters into a series of glyphs ready for display. ScriptShape supersedes the functionality provided by the GetCharacterPlacement API but is quite similar in the type of data it returns.
ScriptShape is a fairly complicated function. It takes as input a single run of text (as identified by the SCRIPT_ITEM / ITEM_RUN structures), and also the SCRIPT_ANALYSIS structure associated with each item-run.
HRESULT WINAPI ScriptShape(
HDC hdc,
SCRIPT_CACHE * psc,
const WCHAR * pwsChars, // in
int cChars,
int cMaxGlyphs,
SCRIPT_ANALYSIS * analysis, // in
WORD * pwOutGlyphs, // out - array of glyphs
WORD * pwLogClust, // out - glyph cluster positions
SCRIPT_VISATTR * psva, // out - visual attributes
int * pcGlyphs // out - count of glyphs
);
Calling this function results in a bewildering array of information. Let’s look at each parameter in turn to understand what they represent.
pscis a pointer to aSCRIPT_CACHEobject. This object must be intialized to NULL beforeScriptShapeis called for the first time.pwsCharsandcCharstogether identify the range of Unicode text (from the original character string) that makes up the current run.analysisis a pointer to theSCRIPT_ANALYSISstructure for each run.pwOutGlyphs[]is a bufferof WORDvalues, which receives the “glyph-indices” that make up the run. A glyph-index is a value unique to a particular font - it is the value which identifies a particular glyph image in that font. The size of thepwOutGlyphsbuffer must be specified with thecMaxGlyphsparameter. WhenScriptShapereturns, the number of items stored inpwOutGlyphsis returned in*pcGlyphs.psva[]points to a buffer ofSCRIPT_VISATTRstructures. This array runs parallel to the glyph-list (pwOutGlyphs), so must be allocated to the same size. Other than being a required input toScriptPlace, I haven’t found any use for theSCRIPT_VISATTRinformation so far.pwLogClust[]is an array of WORD values. There is oneWORDfor every character (16bitWCHAR) in the run of text, so each element ofpwLogClustcorresponds exactly to a character position within the original text. This also means that the size of thepwLogClustbuffer must be the same length as the run of text -cCharsunits long to be exact.
The most important parameter here is the pwLogClust[] array, the contents of which can be used to map between logical character positions and glyph-cluster positions. We will be looking at this array in more detail in the next tutorial.
Font Fallback
The majority of fonts do not support the full range of characters as defined by Unicode. In fact I don’t know of any font which can display all Unicode scripts and languages. One of the nearest is “Arial Unicode MS” - which is available on the Microsoft Office CDs - but even this font only has around 55,000 characters available. Missing glyphs in a font usually (but not always) results in those little square boxes being displayed.
Applications usually solve this problem by utilizing specific fonts for each Unicode script type. This process is referred to as Font Fallback, and is implemented when the primary display font (say, for a text-editor) does not contain the appropriate glyphs to render all characters in a string. An internal lookup-table is searched for a ‘backup font’, from which the required glyphs can be substituted in favour of the missing glyphs in the primary font.
Font-fallback is not handled by the low-level Uniscribe API - only the ScriptString API has this facility. All Uniscribe-based applications are therefore required to have a built-in list of fallback fonts. For this reason I have decided not to implement Font-fallback in UspLib. It will be Neatpad’s responsibility to handle font-fallback, and substitute fonts can be specified in the ATTR style-runs when analysing each line of text.
5. ScriptPlace
ScriptPlace takes the output of ScriptShape (the glyph-index-list and SCRIPT_VISATTR list) and generates glyph advance-width information. Advance-widths are simply the offset in pixels from one glyph to the next. This information is returned in an array of integers (piAdvance), which can be used to position the output coordinates when displaying text and also for mouse hit-testing.
HRESULT WINAPI ScriptPlace(
HDC hdc,
SCRIPT_CACHE * psc,
WORD * pwGlyphs, // in - the results from ScriptShape
int cGlyphs, // in - number of glyphs in pwGlyphs
SCRIPT_VISATTR * psva, // in - from ScriptShape
SCRIPT_ANALYSIS * analysis, // in - from the ITEM_RUN
int * piAdvance, // out - array of advance widths
GOFFSET * pGoffset, // out - array of GOFFSETs
ABC * pABC // out - pointer to a single ABC structure
);
Instead of accepting a buffer of WCHAR characters as input (as did ScriptShape), ScriptPlace requires the buffer of glyph-indices that were produced by ScriptShape. The parameters of note are:
pwGlyphs[](and the correspondingcGlyphs) is the same array of glyphs as returned byScriptShape.psva[] is theSCRIPT_VISATTRarray returned byScriptShape.piAdvance[]points to a buffer of integers, which will receive the list of advance-widths for the run. There is one entry inpiAdvancefor each glyph inpwGlyphs. ThepiAdvancearray must therefore be allocated to the same size aspwGlyphs.pGoffset[]points to a buffer ofGOFFSETstructures. These structures identify the offset of each glyph as it should be displayed. MSDN confusingly documents this parameter as a singleGOFFSETstructure - howeverpGoffsetmust also be allocated to the same length as thepwGlyphsarray.
Finally, the width of the item-run is represented by the ABC structure pointed to by the pABC parameter. The total width of each run can be calculated using the following expression:
runWidth = abc.abcA + abc.abcB + abc.abcC;
Note that the same value can also be calculated by summing together all of the integers in the piAdvance array.
for(i = 0; i < uspData->itemRunCount; i++)
ShapeAndPlaceItemRun(hdc, &uspData->itemRunList[i]);
ScriptPlace is so dependent on the results of ScriptShape that the two functions are usually called together and isolated in a wrapper function. The ShapeAndPlaceItemRun function is used to this effect, and is called once for each item-run in the string.
Tab Expansion
Handling tabs is really easy with Uniscribe, even though there is no built-in support. The thing to understand is, any character in the original text-string will always be represented by at least one glyph after ScriptShape is called. This is even true for non-displayable control-characters such as carriage-returns, spaces, and of course tab characters.
To illustrate this idea, an example string “Hello” will be used, in which has two TAB characters embedded:
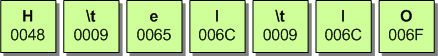
The table below holds the results after calling ScriptShape and ScriptPlace on this text-string:
| Array | [0] | [1] | [2] | [3] | [4] | [5] | [6] |
| pwGlyphs[] | 43 | 3 | 72 | 79 | 3 | 79 | 82 |
| piAdvance[] | 165 | 0 | 102 | 64 | 0 | 64 | 115 |
Notice that the tab-characters have both been represented by a glyph-index of “3”. Although this glyph-index is only valid for a specific font, it represents the ’non-displaying’ glyph - that is, a glyph with no visual representation. More interesting though is the resulting widths of these ‘invisible’ glyphs, which are initially set to zero “0”.
The normal course of action once we have got to this stage is to call ScriptTextOut, with the generated widths+glyphs shown above. This would result in the following:
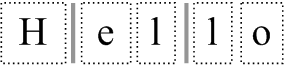
The dotted-outline is purely used here to bring across the concept of each glyph being an individual entity. Also notice the two vertical bars which are supposed to represent the (currently) zero-width tab characters.
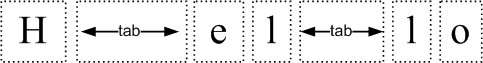
The process of tab-expansion is straight-forward. All we need to do is to modify the individual width-entries for tabs inside the width-list. Once this is done all drawing and mouse hit-testing will use the modified glyph-widths, resulting in extra space being allocated where the tab characters would be.
Tab-expansion must obviously occur after ScriptShape and ScriptPlace have been called. After all item-runs have been processed in this way, UspAnalyze calls another internal function - ExpandTabs:
BOOL ExpandTabs(USPDATA *uspData, WCHAR *wstr, int wlen, SCRIPT_TABDEF *tabdef);
SCRIPT_TABDEF is a standard Uniscribe structure used for ScriptStringAnalyze. It contains information about the tab-stops in a string (size and locations). I have used this same structure for UspLib purely to be consistent.
Applying Attributes
UspLib supports variable length attribute-runs when styling a string of Unicode text, using an array of ATTR structures. Although Neatpad does not take advantage of this facility (it just sets each ATTR to “1” unit long), the possibility still exists for variable-length runs to be specified.
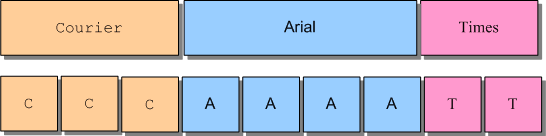
Whilst this is not a problem in itself, processing variable length style-runs at the same time as displaying runs of glyphs can get very complicated. To simplify this matter UspLib always flattens any user-supplied attribute-run, and keeps an internal copy inside the USPDATA object. The flattened run-list is allocated to the same length as the original Unicode string, and contains exactly one ATTR structure per original Unicode character.
UspApplyAttributes(USPDATA *uspData, ATTR *attrRunList)
The UspApplyAttributes (above) is used to update the style-run information belonging to a USPDATA object, and is called by UspAnalyze as part of the string-analysis process. However this function can be called at any time after a string has been analyzed. Note that only the colour-information is updated on subsequent calls to UspApplyAttributes - as reapplying font information would require the entire string to be re-analyzed.
UspAnalyze
We have now covered enough ground to complete the implementation of UspAnalyze. All of the related code for this analysis phase is located in the UspLib.c file. The functional break-down of the analysis is shown below.
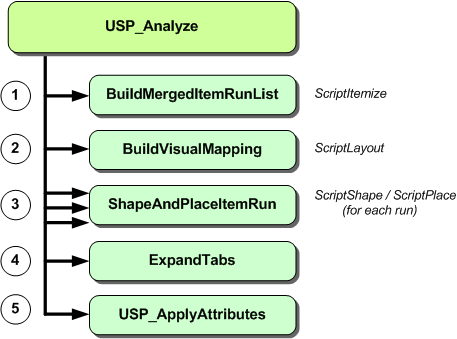
The result of all this work is a single USPDATA object, which contains all of the information necessary to display a string of Unicode text.
typedef struct _USPDATA
{
//
// Item-run information
//
int itemRunCount;
ITEM_RUN * itemRunList;
int * visualToLogicalList;
//
// Logical character/cluster information (1 unit per original WCHAR)
//
int stringLen; // length of current string (in WCHARs)
WORD * clusterList; // logical cluster info
ATTR * attrList; // flattened attribute-list
//
// Glyph information for the entire paragraph
// Each ITEM_RUN references a position within these lists:
//
int glyphCount; // count of glyphs currently stored
WORD * glyphList;
int * widthList;
GOFFSET * offsetList;
SCRIPT_VISATTR * svaList;
//
// external, user-maintained font-table
//
USPFONT * uspFontList;
} USPDATA, *PUSPDATA;
The listing above details the USPDATA structure. For the purposes of clarity I have omitted several ‘house-keeping’ fields which are not required for this discussion.
One of the major difficulties when dealing with Uniscribe is knowing what to do with the huge amount of information that is generated. The strategy that I have taken with UspLib is to keep all information inside the USPDATA object. The “per-run” glyph information is concatenated into several large buffers (glyphList, widthList etc). Each ITEM_RUN refers to a certain range of data within each of these large buffers, using the ITEM_RUN::glyphPos and ITEM_RUN::glyphCount fields.
There are basically two approaches with Uniscribe - and can be categorized as Speed vs Memory consumption. The first strategy is to gather together all the information generated by the Uniscribe APIs into one object. This has the advantage of being quick in operation, because the ‘analysis’ phase (itemization, shaping etc) happens one time only. After this the glyph data is stored away and then reused each time the text is displayed.
The other approach is to conserve memory, by only allocating buffers when necessary, and repeatedly calling ScriptShape/Place each time glyph information is required. The advantage has already been mentioned, but the disadvantage is performance loss. Re-shaping item-runs each time they are displayed will be quite alot slower - and considering that a text-editor will need to redraw it’s display every time the mouse-selection changes, this strategy is something that I want to avoid.
For UspLib I have opted for the speed (resource-heavy) approach.
Coming up in Part 14
We still haven’t drawn any text but it won’t be long before we do. The next tutorial will focus on the UspTextOut function, and will demonstrate how to display styled Unicode text by taking the output from ScriptShape and ScriptPlace, and applying the attribute-runs stored in the USPDATA object.