Introduction to Unicode
17 minute read •
The user-interface for the TextView has progressed enough to allow us to switch our attention back to the TextDocument. I am now concentrating on adding full Unicode support to Neatpad. Because Unicode is such a complicated subject I won’t attempt to tackle it all at once so instead I will split the various aspects of Unicode across several tutorials.
The first Unicode topic (Part 8 - what you are reading now) will be an introduction to Unicode and the various encoding schemes that are in common use. There won’t be any code download as this will be purely a discussion about Unicode to make sure everyone understands the various issues. The next Unicode topic (Part 9) will look at how to incorporate the concepts discussed here into Neatpad - so will focus on loading, storing and processing Unicode data. The rest of the Unicode topics will focus on the issues surrounding the display of Unicode text - and will include complex script support, bi-directional text and the Uniscribe API.
Unicode Myths
Before we start properly it may be worth dispelling the most common myths about Unicode - and hopefully by the end of this article you will have a good idea about what Unicode is all about.
The most common incorrect statement I see about Unicode is this: “In Unicode all characters are two bytes long.”
This is totally incorrect. The Unicode standard has always defined more than one encoding form for its characters - with UCS-2 originally being the most common. However since Unicode 2.0 there no longer exists any encoding scheme which can represent all characters using two bytes (read about UTF-16 further down the page).
It doesn’t help that even Microsoft gets it wrong in it’s own documentation sometimes with statements such as “Unicode is a wide-character set”. Well, they’re half-way right - on Windows at least, Unicode strings are typically encoded as UCS-2/UTF-16, but it is quite misleading to claim that Unicode is a “wide-character-set” because it is so much more than that.
The next most common question you hear Windows programmers asking is “How do I convert a UNICODE string to a UTF-8 string?”. This is a question usually asked by somebody who doesn’t understand Unicode. A UTF-8 string is a Unicode string so it cannot be converted. Probably the person asking the question meant “how to I convert between this UCS-2 formatted string and UTF-8?”. Of course, the answer in this case would be the WideCharToMultiByte() API call.
One last misconception is that the wchar_t “wide character” type is 16bits. This is maybe true on Windows platforms, but the C language makes no such assumption about the width of a wchar_t type - it can be as wide as the C compiler wants it to be in order to represent a single “wide character”, and on UNIX and Linux wchar_t is commonly a 32bit quantity.
Code Pages and Character Sets
Everyone is familiar with the ASCII character-set, which encodes 128 unique character values (0-127) using 7bit integers. Most people are also aware of the existance of the ANSI character-set(s), which use a full 8bit byte to encode 256 (0-255) character values. And it is probably fair to say, most people are fully aware that an 8bit byte is not sufficient to encode all of the world’s writing systems, except maybe a very few European languages.
These “byte-based” character sets are often referred to as Single-Byte-Character-Sets, or SBCS for short. Most of the 8bit character-sets keep the bottom 128 characters as ASCII, and define their own characters in the top “half” of the byte. There are many, many single-byte character-sets in existence.
These extra character-sets are referred to as codepages (a traditional IBM term), and are each identified by a unique codepage number which is usually defined by the ANSI/ISO organisations. For example, the familiar ANSI codepage used by Windows is 1252. A Windows application could set it’s codepage number to tell Windows from which character-set it wanted to work with.
Of course a single 8bit character was never going to be enough to represent the rest of the world’s writing systems. The east-Asian languages especially needed a different approach and this is where Double-Byte-Character-Sets (DBCS) come into play. With these character-sets, a character can be represented by either one or two bytes. There are many other character-sets which share this design and Microsoft refers to them all as Multi-Byte-Character-Sets (MBCS) in it’s documentation. The one thing all these character sets have in common is their complexity - they are all quite difficult to work with from a programming perspective.
You may be familar with the many APIs and support libraries for dealing with MBCS strings such as CharNext, CharPrev, _mbsinc, _mbsdec etc. All of these APIs are designed for a program to work with legacy character-sets - and rely on the correct codepage to be setup before an application can display text correctly.
Note that all of these concepts are really quite out of date now. SBCS, MBCS and DBCS, and the whole idea of codepages all belong in the past and thankfully we no longer have to worry about them.
What is Unicode?
There seems to be alot of confusion surrounding Unicode. This is mostly due to the fact that Unicode has evolved quite significantly since its first release in 1991. A great deal of information has been written about Unicode during this time and much of the earlier information is now inaccurate. Almost 15 years later Unicode is now at version 4.1 - and your perception of Unicode has probably been most influenced depending on when you first became exposed to the subject. Understanding the history of Unicode is almost as important as understanding Unicode itself.
Unicode is the universal character encoding standard for representing the world’s writing systems in computer-form. It is also a practical implementation of the ISO-10646 standard. The Unicode consortium (represented by several international companies including Microsoft and IBM) develops the Unicode standard in parallel with ISO-10646. Often you will see terms from each standard used interchangably but really they refer to the same thing.
The main purpose behind Unicode is to define a single code-page which holds all of the characters commonly in use today. At its heart Unicode is really just a big table which assigns a unique number to each character as defined by ISO-10646. Each of these numbers in the Unicode codepage is referred to as a " code-point". The following are examples of Unicode code-points:
| U+0041 | “Latin Capital Letter A” |
| U+03BE | “Greek Small Letter Xi” |
| U+1D176 | “Musical Symbol End Tie” |
The standard convention is to write " U+" followed by a hexadecimal number which represents the codepoint value. Often you will also see a descriptive tag next to each code-point, which gives the full name to the codepoint as defined in the Unicode standard.
The Unicode standard can represent a little over one million code-points. With version 4.0 around 96,382 characters have been assigned to actual code-points, leaving approximately 91% of the encoding space unallocated. With most of the world’s writing systems already encoded (including the garantuam Chinese-Japenese-Korean character-sets), this leaves a lot of expansion for future use.
A single code-point within this encoding space can take a value anywhere between 0x000000 and 0x10FFFF. Unicode codepoints can therefore be represented using 21-bit integer values. It is no accident that these numbers were chosen and if you read into the UTF-16 format more deeply you will understand why Unicode has been limited in this way. It is important to note that both the Unicode consortium and ISO pledge to never extend the encoding-space past this range.
UTF-32 and UCS4
Of course, a 21-bit integer is a bit of an “odd” sized unit and doesn’t lend itself well to storage in a computer. As a result of this, Unicode defines several Transformation Formats with which to encode streams of Unicode code-points. The three most common are “UTF-8”, “UTF-16” and “UTF-32”.
Out of these three, UTF-32 is by far the easiest to work with. Exactly one 32-bit integer is required to store each Unicode character. However, UTF-32 is very wasteful - 11 bits out of the 32 are never used, and in the case of plain English text encoded as UTF-32, this means 75% waste overall. The table below illustrates how a 21bit integer (represented with ‘x’s) is encoded in a 32bit storage unit:
| Unicode | UTF-32 |
|---|---|
| 00000000 - 0010FFFF | 00000000 000xxxxx xxxxxxxx xxxxxxxx |
Some operating systems (like UNIX variants) use UTF-32 internally to process and store strings of text. However UTF-32 is rarely used to transmit and store text-files simply because it is so space-inefficient and because of this, it is not a commonly encountered format.
UCS-2
UCS is a term defined by ISO-10646 and stands for Universal Character Set. When Unicode was first released the primary encoding scheme was intended to be the UCS-2 format. UCS-2 uses a 16bit code-unit to store and represent each character. At the time this was considered an adequate scheme because only 55,000 characters had been assigned to Unicode code-points thus far - this meant that every Unicode character (at the time) could be represented by a single 16bit integer. Unfortunately we are still paying the consequences for this incredibly short-sighted decision.
Even before Unicode was developed there existed many “wide character sets” which required more than one byte to store each character. The most notable were IBM’s DBCS (double-byte-character-set), JIS-208, SJIS and EUC to name just a few. To support the various wide-character sets, the wchar_t type was introduced into the C standard in the late 80s (although it wasn’t ratified until 1995). The wchar_t type (and wide-character support in general) provided the mechanism to support these wide-character sets.
The companies which backed the UCS-2 format pledged support for Unicode. Microsoft in particular engineered its Windows NT OS line to be natively “Unicode” compatible right from the outside, and used the 16bit UCS-2 wide-character strings to store and process all text.
UTF-16
In 1996 Unicode 2.0 was released, extending the code-space beyond 65,535 characters - or what is known the Basic Multilingual Plane (BMP). It was obvious that a single 16bit integer was insufficient to encode the entire Unicode code-space, and the UTF-16 format was introduced along with the UTF-16 Surrogate Mechanism. Importantly, UTF-16 is backward compatible with UCS-2 (it encodes the same values in the same way).
In order to represent characters from 0x10000 to 0x10FFFF, two 16bit values are now required - which together are called a Surrogate Pair. This also means that there is no longer a 1:1 mapping between the 16bit units and Unicode characters. The two 16bit values must be carefully formatted to indicate that they are surrogates:
- The first 16bit value is called the “high surrogate” and must have the top 6 (of 16) bits set to “110110”. This leaves 10 unused bits for storing values from 0xD800 to 0xDBFF, providing a range of 1024 characters.
- The second 16bit of the pair is called the “low surrogate” and must have the top 6 bits set to “110111” - this results in values from 0xDC00 to 0xDFFF, again providing a range of 1024 characters.
This “surrogate range” between D800 and DFFF was “stolen” from the one of the previously named “Private Use Areas” of UCS-2. When combined together a surrogate-pair provides 1024x1024 combinations, which results in 0x100000 (1,048,576) additional codepoints outside of the BMP. The table below illustrates how the Unicode code-space is represented using UTF-16.
| Unicode | UTF-16 |
|---|---|
| 00000000-0000FFFF | xxxxxxxx xxxxxxxx |
| 00010000-0010FFFF | 110110yy yyxxxxxx 110111xx xxxxxxxx |
So in essence, UTF-16 is a variable-width encoding scheme much like the multi-byte UTF-8. You may be wondering (as I did) exactly what the advantage is now that UTF-16 is no longer a fixed-width format. It would be interesting to see if UTF-16 would be in use today had UTF-8 been available right from the start.
Even without the variable-width problem, using UTF-16 from a C/C++ perspective is pretty tiresome because of the strange wchar_t type and the L"" syntax for widecharacter string literals. Understand that UTF-16 is the dominent encoding format at the moment. Microsoft Windows and Macintosh OSX both use it for their operating systems, and the Java and C# languages also use UTF-16 for all string operations. UTF-16 is unlikely to go away any time soon.
Actually, the variable-width nature of UTF-16 and the slight complexity it now brings pales into insignificance when compared with the nightmare of displaying Unicode. It really doesn’t matter that a string is in multibyte format - even with UTF-32 one codepoint does not necessarily map to one visible/selectable “glyph”, as we will find out over the next parts of this series.
UTF-8
One very popular encoding format is UTF-8, officially presented in 1993. A common misconception is that UTF-8 is a “lesser” form of UTF-16. Nothing could be further from the truth - it encodes the exact same Unicode values as UTF-16 and UTF-32, but instead uses variable-length sequences of up to four 8-bit bytes. This means that UTF-8 is a true multi-byte format. Much of the text on the Internet (such as in web pages and XML) is transmitted using UTF-8, and many Linux and UNIX variants use UTF-8 internally.
The way UTF-8 works is quite clever. The MSB (most-significant-bit) in each byte is used to indicate whether a character-unit is a single 7bit ASCII value (top bit set to “0”), or is part of a multibyte sequence (top bit set to “1”). This means that UTF-8 is 100% backward compatible with plain 7bit ASCII text - of course, it was designed for this very purpose. The design allows older non-Unicode software to handle and process Unicode data with little or no modification.
There are actually three basic constructs in UTF-8 text:
- Plain ASCII text (characters in the range 0-127) is represented as-is with no modification.
- Lead-bytes identify the start of a multibyte sequence. The number of “1” bits at the top of a lead-byte denote how many bytes there are in the sequence, including the lead-byte. So a byte with “110” at the start denotes a 2-byte sequence and a byte with “1110” denotes a 3-byte sequence, and so-on. The remaining bits at the bottom of the lead-byte are used to store the first part of the 21-bit Unicode value.
- Trail-bytes always start with “10” as the top-bits, with the lower 6 bits being used to store the remaining bits from the Unicode value. A trail-byte must always follow a lead-byte - it cannot ever appear on its own.
So, a Unicode value in the range 0-127 is represented as-is. Values outside of this range (0x80 - 0x10FFFF) are represented using a multibyte sequence, comprising exactly one lead-byte and one-or-more trail-bytes. Each Unicode character with a value above 0x7F has it’s bits distributed over the “spare” bits in the multibyte sequence.
The following table illustrates this concept:
| Unicode | UTF-8 |
|---|---|
| 00000000-0000007F | 0xxxxxxxx |
| 00000080-000007FF | 110xxxxx 10xxxxxx |
| 00000800-0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000-001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000-03FFFFFF* | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000-7FFFFFFF* | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Notice that the last two rows have been marked with an asterisk: they are illegal forms of UTF-8. Although UTF-8 can theoretically be used to encode a full 31bit integer using lead-bytes 111110xx and 1111110x, these are overlong sequences because they represent numbers outside of the 0-10FFFF unicode range. Remember that this “artificial” limit has been imposed due to the UTF-16 surrogate mechanism.
Unicode text files
If you have ever used the regular Notepad on Windows NT you may be aware that text files can be saved in several formats - ASCII, Unicode (which is really UTF-16), Unicode-Big-Endian (which is big-endian-UTF-16) and lastly UTF-8.
The problem with text-files on Windows (and probably most other operating-systems) is that there is no way to tell what type of text is contained within a file - because plain-text files (by their very nature) provide no such facility. The Unicode standard therefore defines a method for tagging a text-file with a “Byte Order Mark” in order to identify the encoding scheme used to save the file. The optional “BOM” sequences are listed below.
| Byte Signature | Unicode Format |
|---|---|
| none | Plain ASCII/ANSI |
EF BB BF | UTF-8 |
FF FE | UTF-16, little-endian |
FE FF | UTF-16, big-endian |
FF FE 00 00 | UTF-32, little-endian |
00 00 FE FF | UTF-32, big-endian |
The table above was taken from the Unicode Standard 4.0. The BOM values are chosen because it would be extremely unlikely to ever encounter those character-sequences at the start of a plain-text document. Of course it is still possible to encounter such files - its just very rare.
With Neatpad, in the absence of any signature the file is treated as plain ANSI text. This is in contrast to how Notepad works - it uses statistical analysis of the file in order to make a ‘best guess’ as to the underlying format, and sometimes gets it wrong.
Relevant reading
The first place you should start is www.unicode.org/faq. This is the official site for Unicode and contains the complete Unicode 4.1 standard. The standard is also available in book (hardback) form.
However if you want a really good book on Unicode then I can recommend “Unicode Demystified” by Richard Gillam. This book gives a really good practical coverage of the many Unicode issues and I found it indispensible whilst researching this project.
The following links may also prove to be useful:
- WIKI page on Unicode
- UTF16 for processing
- Characters vs Bytes
- Forms of Unicode
- Power user’s guide to multilingual text editors
- A tutorial on character-code issues
- UTF-8 and Unicode FAQ for Unix/Linux
Unicode C++ projects in Windows
Seeing as we want to support Unicode in Neatpad, it makes sense for us to use the native Unicode support provided by the Windows operating systems. In practise this means using the “Wide-character” Unicode APIs - which are basically UTF-16/UCS-2. There is a certain technique to writing Unicode-enabled applications under Windows which every programmer should be aware of.
- The first step in creating any Unicode Windows project is to enable support for the wide-character APIs. This is usually achieved by defining the
UNICODEand_UNICODEmacros for every source-file in your project (and removing macros such as_MBCSand_DBCS). The reason two macros are required is simple:UNICODEis used for the Windows/Platform SDK libraries, whereas_UNICODEis used for the standard C/C++ runtime libaries. - The second step is to
#include <tchar.h>- this file contains many “support macros” that are very useful for Unicode projects. - The third step is to define any character type as
TCHAR- this is another macro and results inWCHARstring types forUNICODEprojects, andcharstring types for regular “non Unicode” projects. - The forth step is to declare all string literals using the
_Tand_TEXTmacros, which are defined in<tchar.h>. These macros control how string-literals are defined. For a non-Unicode project these macros do nothing, however for a UNICODE project all string-literals have theL""string prefix attached. - The fith and final step is replace all calls to C-runtime string functions (such as
strcpy) with their_tcsequivalent (e.g._tcscpy). Although these equivalents can all be found in the<tchar.h>runtime header, there is a simple trick to obtaining the ‘_t’ name from the original - just replace the ‘str’ part with ‘_tcs’.
You’ve hopefully got the idea that Unicode programming in Windows relies heavily on the C/C++ preprocessor for support. The example below illustrates all of these concepts together.
#include <windows.h>
#include <tchar.h>
TCHAR szFileName[MAX_PATH];
// calling one of the standard-C calls
_tcscpy(szFileName, _T("file.txt"));
// calling one of the Platform-SDK APIs
CreateFile(szFileName, GENERIC_READ, ...);
Because TCHAR, _tcscpy, _T and CreateFile are really MACROs, with UNICODE defined our sample program becomes:
WCHAR szFileName[MAX_PATH];
_wcscpy(szFileName, L"file.txt");
CreateFileW(szFileName, ...);
Note that the WCHAR character-type is actually another macro which is defined as wchar_t. The Visual-C compiler treats this wide-character type as a 16bit quantity. Don’t assume that this is true across all platforms - for example on UNIX systems wchar_t is usually a 32bit quantity because the native Unicode format is UTF-32 on these systems.
Without the UNICODE setting defined our sample program becomes an ordinary “C” program:
char szFileName[MAX_PATH];
strcpy(szFileName, "file.txt");
CreateFileA(szFileName, ...);
Rather than putting UNICODE and _UNICODE at the top of every source-file we will make things easier on ourselves. The last thing we need to do is configure the Neatpad and TextView projects to build as Unicode applications on a project-wide basis. Rather than modify the existing projects, we will add two new project configurations (one for Debug and one for Release). This will allow us to build the an ASCII-only Neatpad, and a Unicode build from the same sourcecode.
Select Build -> Configurations menu item from Visual Studio.
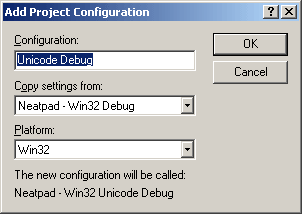
The new configurations are created by using the existing non-unicode projects as templates. We need to perform this task for both the Neatpad and TextView projects, and for each Debug and Release build as well. Once done we will have four project configurations for each project - Debug, Release, Unicode Debug and Unicode Release.
Coming up in Part 9
Hopefully this has been a useful introduction to Unicode. I felt it was necessary to cover the basics first before diving straight in as Unicode is such a complicated subject. The next part of this series will look at taking the ideas presented here and integrating directly into Neatpad.